🦍 Serverless API on AWS: NodeJS + Lambda + DynamoDB
From basic concepts until deployment of a Serverless API on AWS

On this post, I’m going to describe how to set up a basic CRUD API written in NodeJS which will run on AWS Lambda and use DynamoDB. We will go through each step from setting up your local environment, explaining about Serverless Framework, creating your DynamoDB table and, by last, writing the API with ExpressJS.
0. The problem
The idea of this post is to give motivation for you to learn about the serverless architecture and get excited about this new wonder of the 21st century.
The API on this post will be written to help an imaginary monkey sanctuary to keep track of their fellow hosts. The specifications request something that can:
- Create a new monkey profile, once it arrives at the location.
- Read all details of one monkey
- List all the monkeys by species ordering by arrival date
- Edit a single monkey information
From the specifications, each monkey can be uniquely identified by a numeric ID, which he’ll receive and carry when arriving at the sanctuary.
With this information, we can start thinking about the database specifications, but for now, let’s set up the local environment.
1. Setting up environment
In order to get the API running in AWS Lambda, it can be quite challenging to understand all the steps that are required to call your code as a normal API. Besides setting AWS Lambda, it would also be necessary to set an API Gateway, configure AMI users and roles, upload yourself the code to S3 and so on. But if you are reading this post it means that what you really want is to have the API up and running, which is why we will use Serverless Framework.
Serverless is your toolkit for deploying and operating serverless architectures. Focus on your application, not your infrastructure.
In order to have it installed on your machine, be sure to follow their very good tutorial here, but I will try to write the most important steps here to have it running.
1.1 AWS Account & IAM User
First things first, be sure to have an account on AWS. With AWS Free Tier, you can have an account with a ton of benefits and things to use for free during your first year. Lambda, for example, allows 1 million calls per month for free for the Free Tier user, so you do not need to worry about that during your first year. Check it out how to get this account on their website.
Now that you have the account, log in on console and then search for the service IAM. Clicking on the menu Users on the left, you will see the list of users you currently have, as shown below:
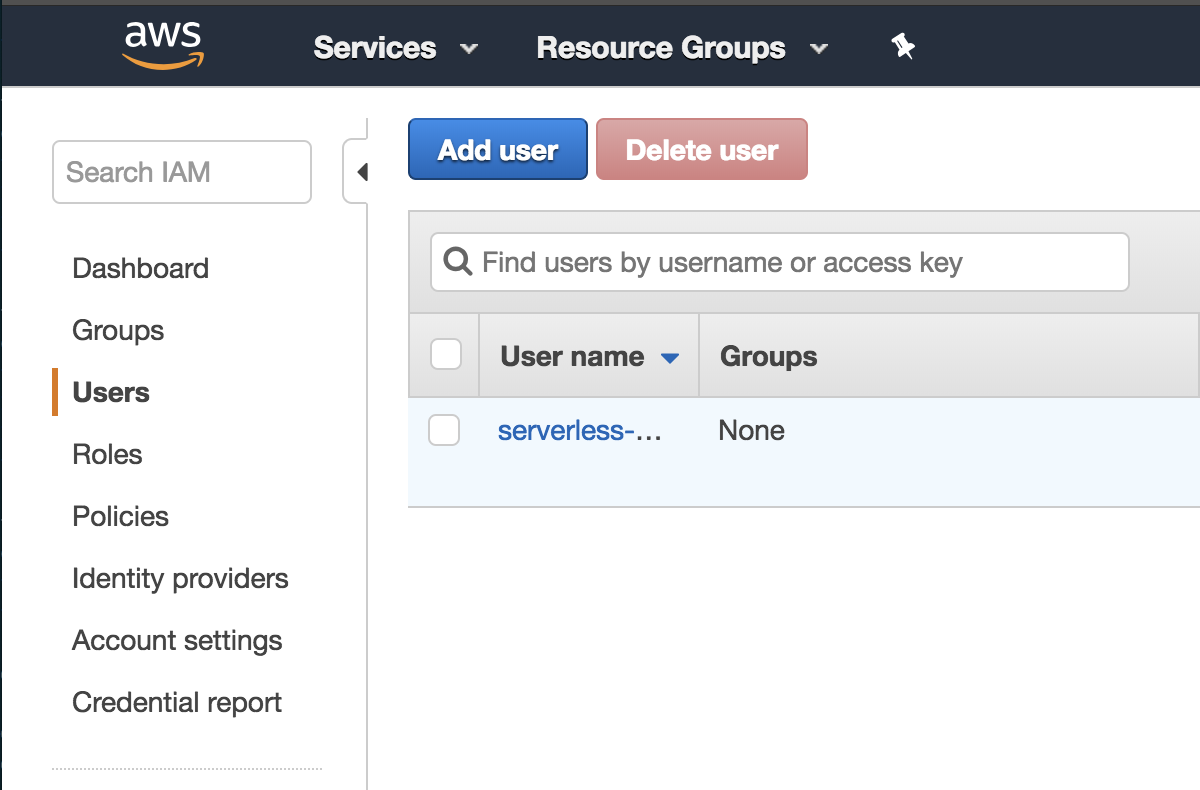
By clicking on the Add User button, we can now create a new user with the right access for your application. Give it a nice and identifiable name (serverless-user, for example) and select programmatic access type.
On the next page, choose to Attach existing policies directly and then select AdministratorAccess. This policy will give access to every AWS services and not need to worry about the right access. Later you can (and should) create another IAM user with a specific policy, but let’s not worry about that.
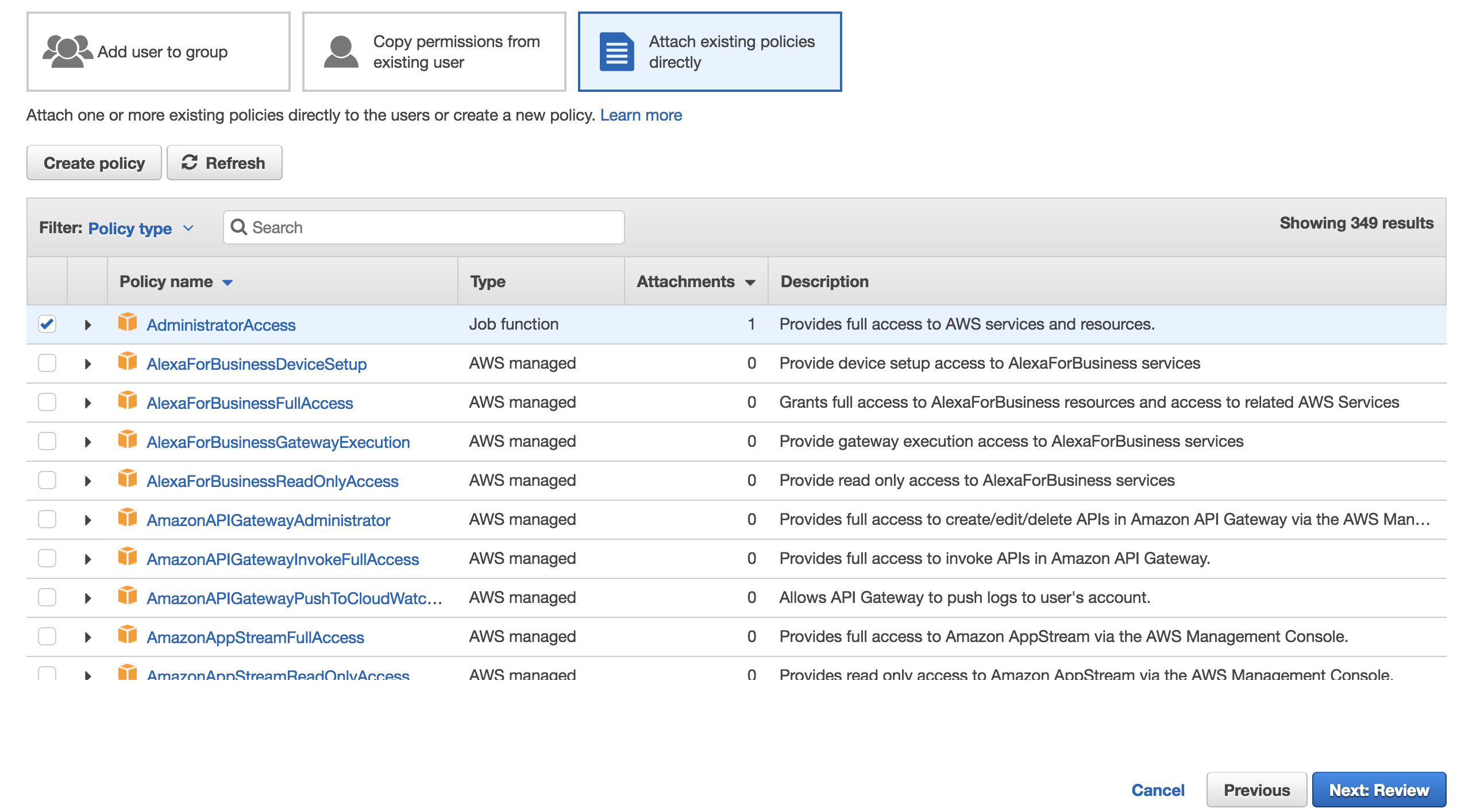
Click on Next a couple of times and you should now have the Access key ID and Secret access key. Keep this information open for a while. We are going to use it in the next subsection.
1.2 AWS CLI
AWS-CLI (Command Line Interface) is a tool to interact with AWS Services from the command line and it is essential for this tutorial. There are many ways to install it, so be sure to follow their documentation. After that, it is important to configure your credentials by running aws configure and then setting your IAM information, like
AWS Access Key ID [None]: <Access key ID>
AWS Secret Access Key [None]: <Secret access key>
If you want, you can already set the desired Default Region Name, such as eu-west-1, and Default Output Format to json.
1.3 Serverless Framework
For this part, you can either follow the Serverless Framework documentation or go through the simplified steps on the blog.
First, be sure to have NodeJS v6.5.0 or later installed and install serverless globally with npm install -g serverless and that’s it! Just to be sure that everything is there, try running serverless version.
So with that one installed, we can now start a new project by running
serverless create --template aws-nodejs --path serverless-api
and done. You now have a basic Serverless Framework project. An important file to take a look here is serverless.yml, but this is not the place to talk about it, so please refer to the docs for any problem.
2. Setting up DynamoDB
Since we now have the basic skeleton of the application, it is time to understand and set up the data storage.
DynamoDB) has extensive documentation that should always be used while developing. So this tutorial will start from the point that the reader knows the basic idea of how tables, items, and indexes work in DynamoDB.
2.1 Defining indexes
By reading the specifications, we know that the table containing monkeys information must have at least three Attributes: id, species and arrival_date. For the simple CRUD operations on a single monkey, we could use Partition key only as Primary Key, since it is a unique value.
But things will get more complicated if we need to list all monkeys by species and order by arrival_date, because scanning and filtering through the database will be an expensive operation. This way a good idea is to have a Global Secondary Index having species as partition key and arrival_date as the sort key.
2.2 Creating the table
While being logged in AWS Console, go to the DynamoDB Service and click on the Create table button. In this example, I set Table Name to be monkey_sanctuary and the Primary Key to be id and type Number. By choosing not to use the default settings, there is a button to Add index and create a secondary index as the picture below shows.
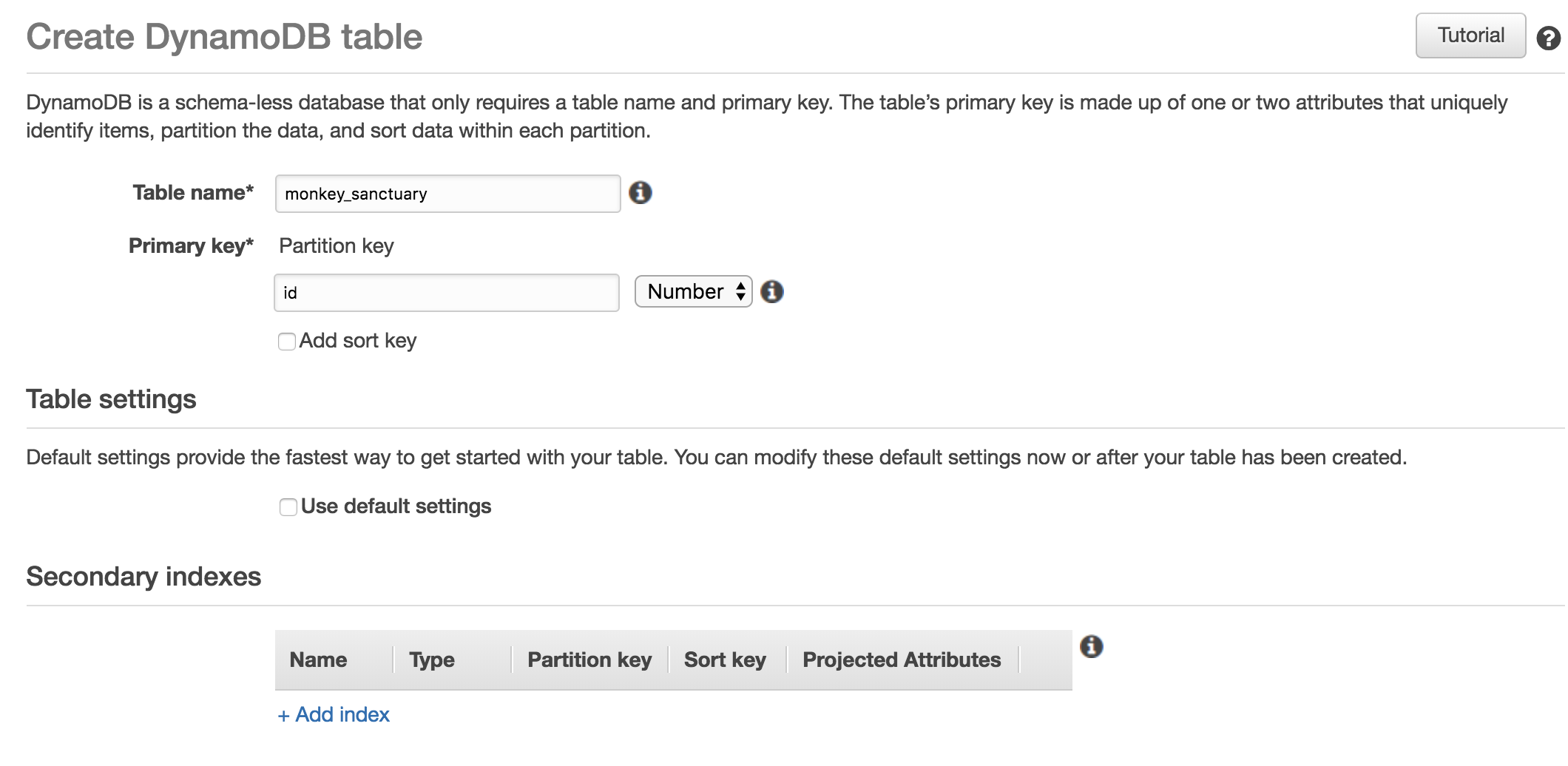
There you can add the following details
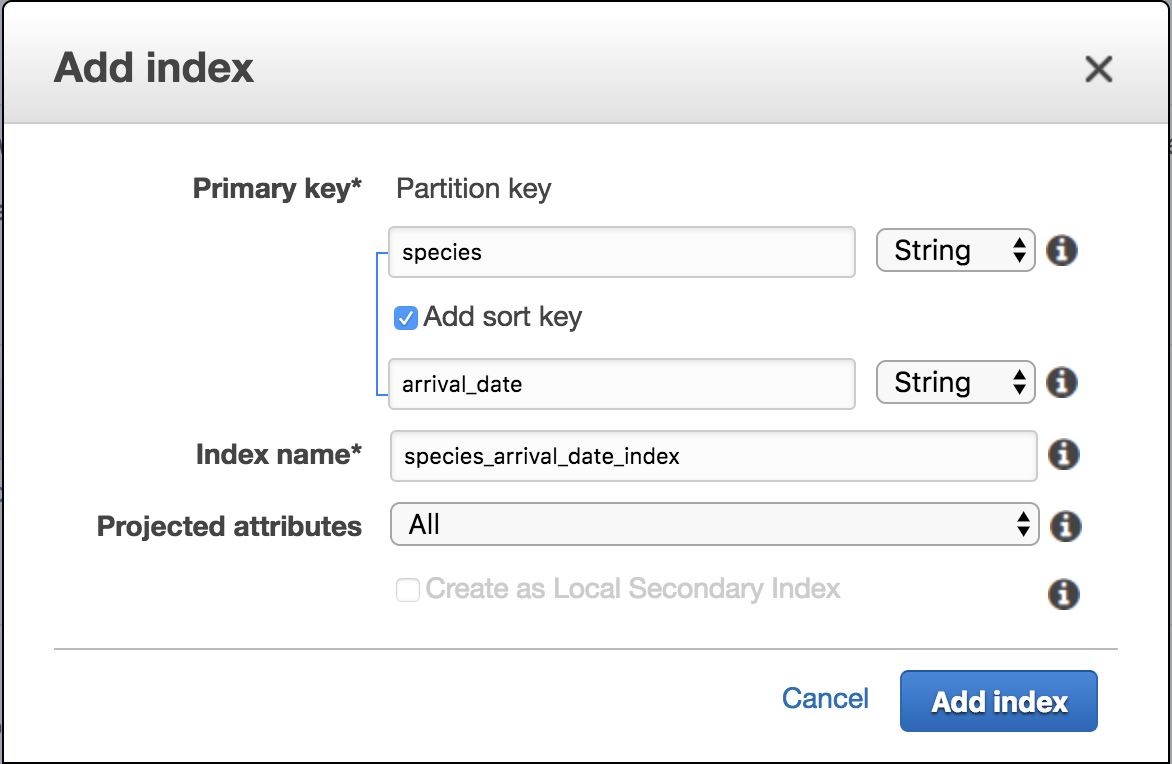
The rest of the information can be left as default. Now scroll to the bottom of the page, Create Table and done: you have just created a new table on DynamoDB.
3. Writing the API
All the code written for this application can already be found on my GitHub here, so on this part of the post, I’m just going to go through some important details of the implementation.
3.1 Preparing dependencies
To start getting the dependencies I’m using npm, so when I say install package-name-1 what I mean is to run npm install package-name-1. But if you want to be sure you are installing the right dependencies just check the package.json file on the GitHub project.
In order to get the project working with AWS, it is necessary to install aws-sdk dependency, together with express, since it is the framework we decided to use since the beginning. And in order to make things even simpler, AWS Labs has a project called AWS Serverless Express, so be sure to also install aws-serverless-express.
By last, I also find it important to install the cors dependency, so that whenever needed you can enable CORS with different options. Check it out their documentation.
3.2 Health endpoint
To write a simple endpoint and test to see if the deploy is working correctly, I created a new file under /src/index.js to have the following code
const express = require('express');
const cors = require('cors');
const awsServerlessExpressMiddleware = require('aws-serverless-express/middleware');
const app = express();
app.use(cors());
app.use(awsServerlessExpressMiddleware.eventContext());
app.get('/health', (req, res) => {
res.send('OK');
});
module.exports = app;
and that’s it. Now we just need to make the handler.js to read from this file with
'use strict';
const awsServerlessExpress = require('aws-serverless-express');
const app = require('./src/index');
const server = awsServerlessExpress.createServer(app);
module.exports = {
app: (event, context) => awsServerlessExpress.proxy(server, event, context),
};
By last, we just to make a couple of changes on serverless.yml so that we have our own function being read from handler.app. So you can delete all of the current code there and change it to
service: serverless-api-monkey-sanctuary
provider:
name: aws
runtime: nodejs6.10
region: eu-central-1
stage: dev
functions:
express:
handler: handler.app
events:
- http: 'ANY /'
- http: 'ANY {proxy+}'
now back to the command line run serverless deploy and wait for the output. It should be something simillar to this:
Now with that URL received, you can send a GET request to https://<YOUR-RANDOM-LETTERS>.execute-api.eu-central-1.amazonaws.com/dev/health and you should get an OK as the response.
Congratulations, you just deployed your first endpoint!
3.2 Creating new monkey
In order to keep things simple, I won’t add details about validating body requests or handling well the return from the API in case something went wrong. This can be the content of a new post since here we are focusing into having a basic CRUD API.
So continuing under index.js we need to prepare a new POST endpoint which will receive a request containing id and species on the body. And in order to query DynamoDB, it is necessary to instantiate a new DynamoDB.DocumentClient and create the item with the following code
const docClient = new AWS.DynamoDB.DocumentClient();
app.post('/monkeys', (req, res) => {
const { body } = req;
const now = new Date();
const params = {
TableName: 'monkey_sanctuary',
Item: {
id: parseInt(body.id, 10),
species: body.species,
arrival_date: now.toISOString(),
},
};
return docClient.put(params).promise()
.then(data => res.json(data))
.catch(err => res.json(err));
});
and that’s it. The body can be easily fetched from the request parameter because there is a new middleware being used called body-parser, so be sure to check the code to see how this was done.
3.2.1 Allowing Lambda to use DynamoDB
Great, now that everything is ready we can redeploy the new code with serverless deploy and send a POST request to the https://…..dev/monkeys containing the JSON {id: 1, species: 'rhesus'}. But when trying to do that, the following error happens:
user **
** is not authorized to perform: dynamodb:PutItem on resource: **arn:aws:dynamodb:eu-central-1:XXXXX:table/monkey_sanctuary**
which makes sense, because we have never allowed the Lambda Function to call the DynamoDB resource. So let’s do that by using the serverless.yml. Below the provider, add the following
provider:
...
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:Query
- dynamodb:GetItem
- dynamodb:DeleteItem
Resource: arn:aws:dynamodb:eu-central-1:XXXXX:table/monkey_sanctuary*
but be sure to change the Resource ARN to your own table. You can find this information on AWS, going to DynamoDB page and selecting the overview of the monkey_sanctuary table. Under Table Details, you can find Amazon Resource Name (ARN). Redeploy the API and now everything should be working!
The reason why Resource need to have the star (*) on the end is because we need to give access to both the table and index, otherwise we would need to give permission to the secondary index as well.
Now when we try to send the same request again, the API will return a successful 200 and the new monkey information can be found on DynamoDB.

3.4 Retrieving and updating
Now that we have that endpoint working, the retrieving and updating will be really similar. Starting with the endpoint to fetch a monkey by id, we could use the following code:
router.get('/:id', (req, res) => {
const docClient = new AWS.DynamoDB.DocumentClient();
const params = {
TableName: 'monkey_sanctuary',
Key: { id: parseInt(req.param('id'), 10) },
};
return docClient.get(params).promise()
.then((data) => {
if (!data.Item) {
return res.status(404).json({ message: 'Id not found' });
}
return res.json(data.Item);
})
.catch(err => res.status(404).json(formatError('Failed to fetch id', err)));
});
One common error here is to try to fetch the monkey id using a string. Since we have defined on the schema that it should be a number, it is necessary to make that conversion as seen in Key: { id: parseInt(req.param('id'), 10) }.
Then using the DocumentClient.get the data stored on DynamoDB will be retrieved within Item key. If nothing is found, we use ExpressJS to return a 404 and a clear message.
The next step to update it will follow the same idea, put in this case we need to call DocumentClient.update and pass a few extra parameters. In this case, we are going to have this endpoint to allow anyone to update extra information on each monkey, which should be passed on the body of the request. The code is the following:
router.put('/:id', (req, res) => {
const docClient = new AWS.DynamoDB.DocumentClient();
const { body: { extra } } = req;
const params = {
TableName: 'monkey_sanctuary',
Key: { id: parseInt(req.param('id'), 10) },
UpdateExpression: 'set extra = :extra',
ExpressionAttributeValues: { ':extra': extra },
};
return docClient.update(params).promise()
.then(() => res.status(204).json({}))
.catch(err => res.status(404).json(formatError('Failed to update information', err)));
});
Since this is a PUT request, there is no need to return anything for the user, except a 204 status code.
3.4 Listing by species
Here comes the interesting endpoint. In order to list many monkeys by species, we need to either Scan or Query. But if you at some point read the documentation of DynamoDB, you’ll soon learn that Scan is very slow once your table starts to grow, which is the reason that we created a secondary index when preparing the table.
So by checking this example we prepared the to query the secondary index only and filter by species with the following code:
router.get('/species/:species', (req, res) => {
const params = {
TableName: 'monkey_sanctuary',
IndexName: 'species_arrival_date_index',
KeyConditionExpression: 'species = :species',
ExpressionAttributeValues: { ':species': req.param('species') },
};
return docClient.query(params).promise()
.then((data) => {
if (!data.Items) {
return res.status(404).json({ message: 'Species not found' });
}
return res.json(data.Items);
})
.catch(err => res.status(404).json(formatError('Failed to fetch monkeys from selected species', err)));
});
One thing to focus here is that the result of this query is inside the key Items, instead of Item as it was before.
Now because of the SortingKey on the Secondary Index, just making this query without any ordering will already return the list ordered by arrival_date.
4. Conclusion
On this post, I showed how to get a simple serverless API deployed on AWS. We have set up our own DynamoDB table and used different functionalities from its Node SDK. We also learned about Serverless framework and how useful it is to get started and deploying your code to AWS. The problem that this post set to resolve was fairly simple with a few endpoints, but this could easily become something a lot more complex with many tables and endpoints, and in this case, everything would continue being simple to program and deploy.
If you want to check, the whole code is on my Github. I hope you enjoyed!